
【実践、OpenCV画像処理】SDカードの認識 ~機械学習編~
March 10, 2022
OpenCV 外観検査 python 機械学習目次
はじめに
おうちにある身近な題材でpython+OpenCVによる外観検査の画像処理を楽しむ本企画。今回はおうちにころがっているSDカードの認識に挑戦してみます。
前回はテンプレートマッチングによりSDカードの認識をやってみました。テンプレートマッチングは正立したテンプレート画像に対して画像中の正立したSDカードしかうまくマッチングしないので、回転して置かれたSDカードでも無理矢理マッチングできるようにするためのコードが膨らみました。
今回は機械学習でSDカードの画像を覚えさせることにより認識させることを試みます。物体認識のツールYOLOv3を使用します。OpenCVは今回は無関係です。
YOLOv3の解説記事はネットに大量に公開されており、本サイトで「車輪の再発明」をしてもしょうがないので、YOLOv3が何者かについては割愛します。筆者は以下の記事でYOLOv3についての理解を深めました。いずれも丁寧に解説されています。
https://rightcode.co.jp/blog/information-technology/learn-yolov3-image-windows10-environment-construction
Windows 10 で YOLOv3 を自前画像で学習させる(環境構築編)【機械学習】
https://rightcode.co.jp/blog/information-technology/learn-yolov3-image-windows10-object-detection
Windows 10 で YOLOv3 を自前画像で学習させる(物体検出編)【機械学習】
https://www.yakupro.info/entry/yolov3-originaldata
物体検出モデルYOLOv3で画像から錠剤を検出する
https://www.yakupro.info/entry/yolov3-da-and-modeleval
YOLOv3のData Augmentationとモデル評価
ちなみに、今回はYOLOv3(YOLO Version3のこと)を使用しましたが、2022年初頭の時点でYOLOv4、YOLOv5を経てYOLOXまで出ています。新しいほど良いのはわかるのですが、古いものほどネットの参考記事が充実しています。YOLOはtensorflowやKerasを使用するのですがこれらのバージョンの下二桁目が変わっただけで動かなくなり途方に暮れることになるので、動作報告のあるネット記事と同じバージョンのライブラリを使うのがコツです。
Take1:機械学習初トライ
まずはネットの記事を参考に、深く考えずに見様見真似でやってみました。
学習用の画像は、以下のようなSDカード表面と裏面を6枚並べてスマホで撮ったものです。表面画像6枚、裏面画像7枚合計17画像を使用しました。
この画像にlabelImg.exeを使用してアノテーションを付与します。この領域がSDカードだよということをAIに教える操作です。画像の一部を載せておきます。
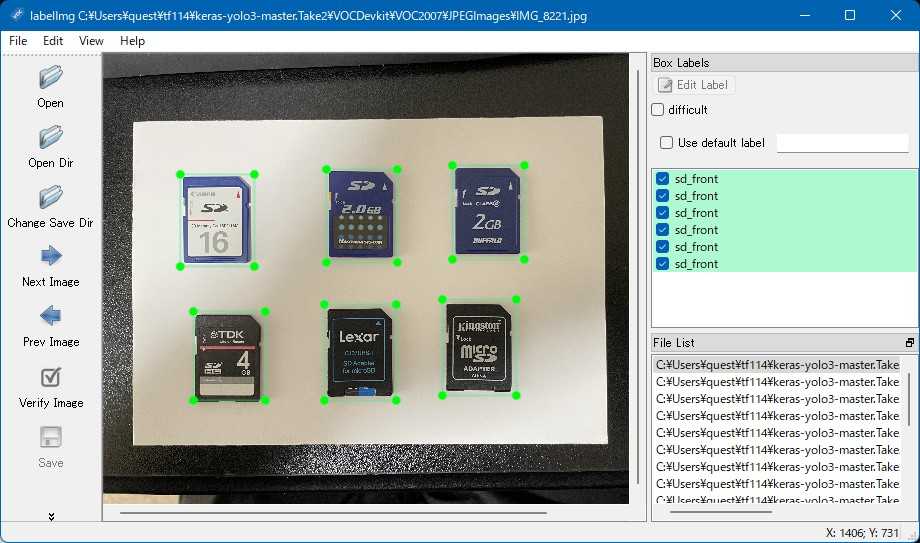
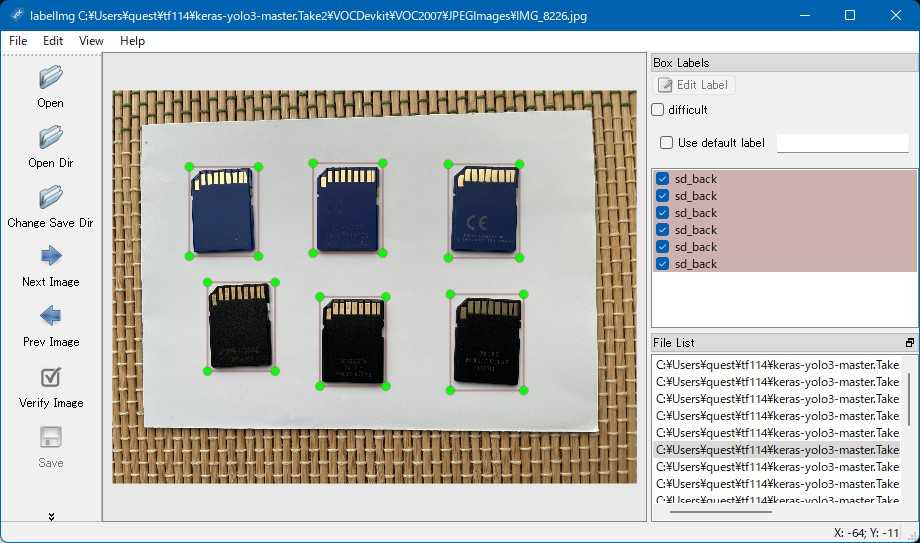
このアノテーション付き画像をひたすら学習させるだけです。学習にかかった時間はIntel NUC i7-8559Uで2時間15分ほどでした。Intel Core i7-8559Uの8スレッドCPUでも歯が立ちません。計算をGPUにやらせると速くなる、NVIDIAのGPUだとライブラリを入れ替えるだけでいいらしいのですが、先立つものが無い…
2時間かけて学習させたモデルで認識させた結果がコレ。なんと学習画像で使用していない全面絵柄のカードも正しく認識している。外接矩形はちょっとヘンだけど。

正立配置しか学習させていないので、回転配置だとこの有様。

正立配置で密接して配置すると、学習時と背景が異なる(学習時の背景は白)ことになるので、成績は悪い。

適当に配置するとほとんどダメ。メモリスティックも混ぜてみたけど。
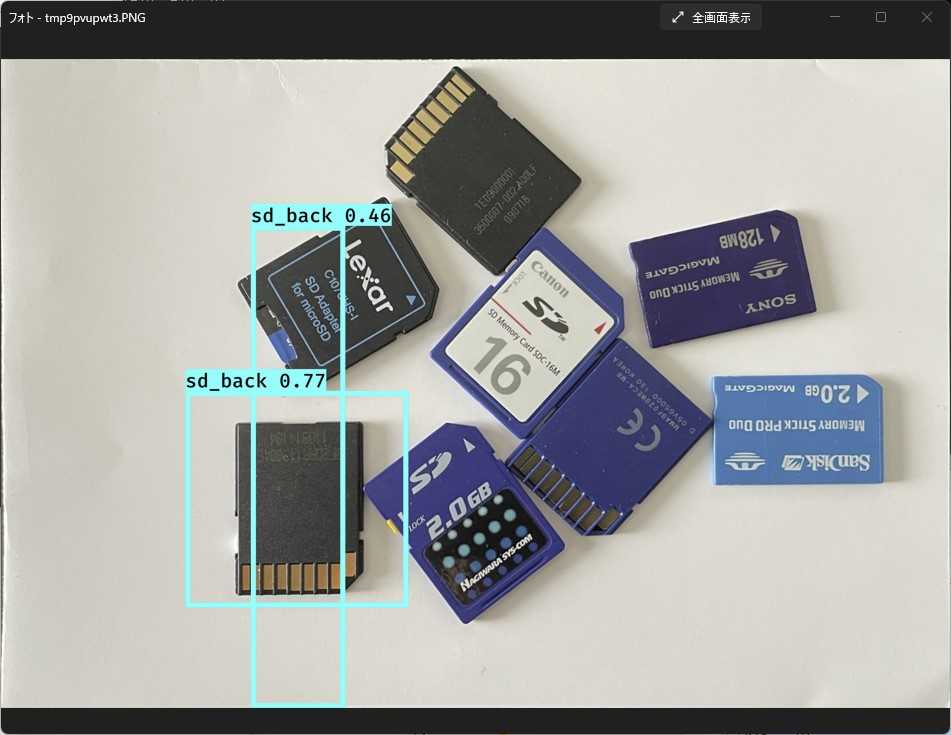
GPU使わずにたった2時間学習させただけでこれだけ楽しめるっていうのはYOLOv3恐るべし。
Take2:姿勢も学習
Take1ではSDカードの正立姿勢のみ学習させてみましたが、これだと当然のことながら正立姿勢の対象物しか認識できません。そこで、回転配置させた姿勢も学習させてみました。
Take1の学習データを加工し、図のように対象物1つにつき10°づつ360°回転させた画像36枚を作成し、表面864画像、裏面864画像、合計1728画像を教師画像としました。回転画像作成と同時にアノテーションも自動で出力するようにしました。

学習にかかった時間はIntel NUC i7-8559Uで30時間46分。ここまでかかるとGPUが欲しくなります。30時間以上負荷が100%に張り付いた状態でファンをブンブン唸らせて学習。寒い冬ならなんとかなるけど、こんなの夏場は絶対に無理。
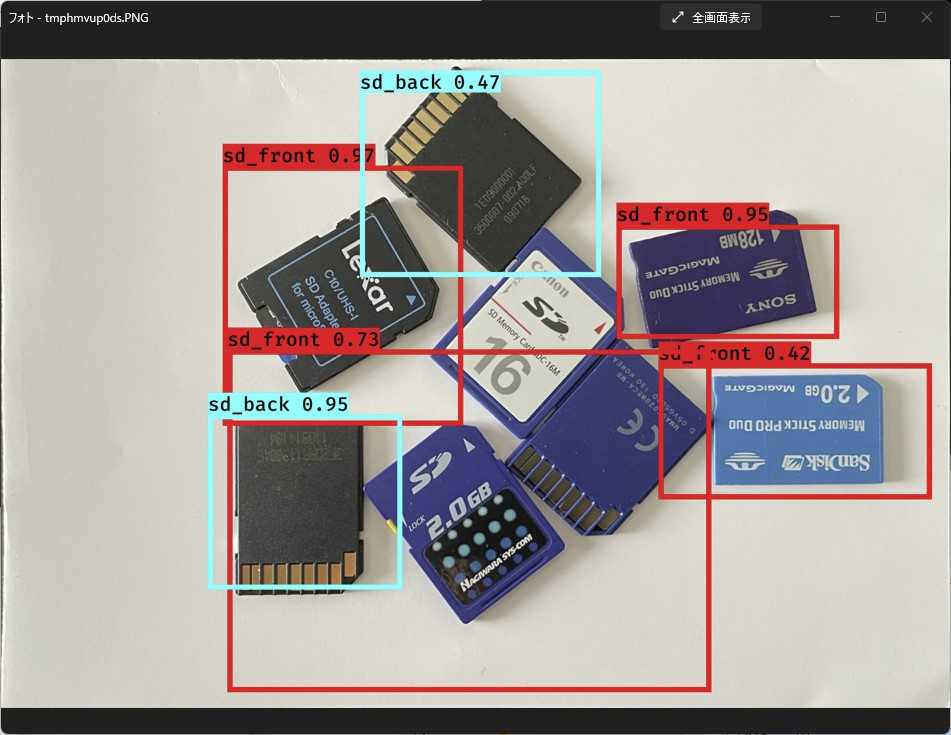
学習させたモデルで認識させた結果がコレ。学習画像で使用していない全面絵柄のカードも正しく認識しています。やはり外接矩形はちょっとヘン。

今度は回転配置でも大丈夫。

正立配置で密接して配置すると全然ダメ。これには思い当たる節があります。対象物の背景は白っぽい無地として学習させた訳だけど、密接して配置すると背景に隣の対象物が映り込んでしまうからうまく見つけられないのだと思う。背景にも別のSDカードが写り込んだ画像も学習させればいいのでしょうけど、背景のバラエティが多くなりすぎるんで、どうしたものか。

バラバラに密接配置してもダメ。こっそり混ぜたメモリースティックはSDカード表面として認識されています。メモリースティックとSDカードでは切り欠きの向きが逆なんで、SDカード裏面と認識されるのかと思ったけどそうではないようです。切り欠きは重要な特徴ではないということだろうか。
Google Colaboratory上での学習
GUPを持っていない筆者としては、AIの学習は楽しいけど、さすがに学習にCPUが高負荷状態で何十時間もかかるのはかなわん、ということでGoogle Colaboratoryを使用することに。誤解を恐れずに例えれば、Google ColaboratoryはGPUのレンタルのようなもの。レンタルとはいってもGPU本体が送られてくる訳ではなく、GPU設置済みのJupyterのような環境がWebブラウザから利用できるというものです。
早速試してみました。 筆者宅のPC(IntelNUC 8i7BEH)で、先のTake2を実行すると、以下のような学習進行状況だったのが、
Train on 778 samples, val on 86 samples, with batch size 32.
Epoch 1/50
24/24 [==============================] - 664s 28s/step - loss: 3256.3576 - val_loss: 566.5378
Epoch 2/50
24/24 [==============================] - 660s 28s/step - loss: 377.1208 - val_loss: 195.7499
Epoch 3/50
24/24 [==============================] - 658s 27s/step - loss: 183.9607 - val_loss: 122.0442
...
Google ColaboratoryでGPUをオンにすると、
Train on 778 samples, val on 86 samples, with batch size 32.
Epoch 1/50
24/24 [==============================] - 83s 3s/step - loss: 2849.6843 - val_loss: 608.0050
Epoch 2/50
24/24 [==============================] - 61s 3s/step - loss: 358.7025 - val_loss: 197.3544
Epoch 3/50
24/24 [==============================] - 62s 3s/step - loss: 174.6034 - val_loss: 133.5854
...
なんと10倍くらい速くなった!と喜んだのも束の間、
(0) Resource exhausted: OOM when allocating tensor with shape...メモリ不足で途中で止まってしまいました。リソースの制約があるようです。Google Colaboratory向けに学習データを少なくするとか工夫が必要そう。
まとめ
今回の実験はnonプログラミング。YOLOv3という出来合いのツールを使ってみただけ。でも、ベルトコンベアで流れてくる対象物の位置を特定するような用途だと、これをそのまま使えそうな雰囲気。
AIに対象物を提示するだけで、それを認識してくれる。すごい時代になったものだ。昔はプログラマーが誤認識を怒られながらせっせと画像処理プログラムを組んでいたんだけど、21世紀の今はAIに学習させるだけ。
NTT西日本のCMで、イチローが「ICTでちょっと違うTomorrow」とか言って、単純作業はAIにまかせてヒトは創造的な仕事に専念できるイケてる未来なんてこと言ってるけど、現実は、ヒトは教師画像の準備とかの誰でもできる単純作業に従事し、大事なことはAIがやるというイケてない未来が待っているということじゃないだろうか。