
【実践、python画像処理】Google Colaboratory上で機械学習
April 18, 2022
OpenCV 外観検査 python 機械学習目次
はじめに
前回は、yolov3を使ってSDカードの姿を学習し認識させてみましたが、機械学習には膨大な計算リソースが必要で、GPUも無い筆者の貧弱なPCでは限界を感じてしまいました。
そこで今回は、GPUが使えるクラウドプラットフォームGoogle Colaboratoryで学習させてみます。
yolov3でSDカードの姿勢を学習
前回のトライは下図のような学習データを、表裏合計864姿勢分を自宅のGPU無しのショボいPCで30時間かけて学習させました。


同じことをGoogle Colaboratory上で学習させると、なんと1時間30分程度で学習が完了してしまいました。Google Colaboratory恐るべし。
Google Colaboratoryはいろいろとリソースの制限がありtrain.pyそのままでは途中で止まってしまい、 57, 76行目のbatch_sizeを32から8に変更して動かしました。
batch_size = 32 # note that more GPU memory is required after unfreezing the body
Google Colaboratoryにより憶えは爆速になったのですが、結果は散々で、
このような画像ならうまく認識できるのですが…

SDカード同士が接触していたりすると全然ダメ…


このまま引き下がるのは癪なので、作戦を変えて再挑戦。
yolov3でSDカードが置かれる状況を学習
単独のSDカードそのものを学習させるのではなく、SDカードが置かれる状況を学習させる必要があるのではないか?
この方針のもと、学習データは図のようにSDカードをランダムに配置したものに変更してみました。


1枚の画像中に9個のSDカードをランダムに配置したものを100画像用意し、学習データとしました。
用意した100枚の画像は、実際にカメラで撮った画像ではなく、図のような1枚の画像にSDカード表面6枚または裏面6枚が写った画像からSDカード部分を抽出し、ランダムに配置して作成しました。


この学習データを使い、Google Colaboratory上のyolov3で学習にかかった時間はたった23分。なんとも爆速なんだけど、Google Colaboratoryの場合、実行させる度に割り当てられるGPUが異なるようで、この時はたまたま高性能のGPUが割り当てられただけなのかも。
認識結果は以下。
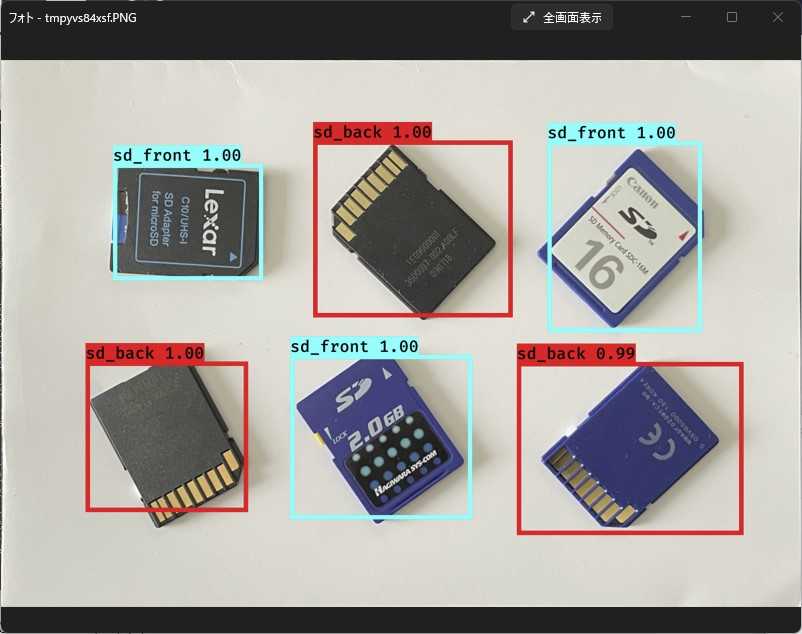
こんどはSDカード同士が接触していても認識できています。こっそり混ぜたメモリースティックはSDカードとして認識されました。一番右端のメモリースティックはSDカードの表と裏の両方として認識されてしまいました。絵柄を見れば表だし、切り欠きの位置を考慮すれば裏として認識されてしかるべきなんで、混乱しているのかも。
ビタビタに密接させて置いても大丈夫。

全く新しい絵柄のSDカードでもスコアは低いものの認識できている。

今度はそこそこ満足な結果でした。やはり学習データが大事ということで。
今回の実験の追試ガイドはこちら。
yolov5でSDカードが置かれる状況を学習
前節と同じことをyolov5でもやってみました。
yolov3よりもyolov5の方がGoogle Colaboratoryとの相性は良いようで、yolov5のパッケージをダウンロードし、パッケージ内にあるrequirements.txtを使用し、
!pip install -r requirements.txtpipで必要なパッケージをインストールするだけでGoogle Colaboratory上でyolov5が使えるようになります。
yolov5にはS, M, L, Xの4つのモデルが用意されていて
前節と同じ教師画像を使用して、Sモデル(いちばん小規模なモデル)を使用して学習を行いました。どれくらいで学習が収束するのか見当がつかないので、とりあえず400Epoch回してみました。Google Colaboratoryで学習にかかった時間は約1時間半。
yolov5では収束状況が可視化されて ./runs/train/exp/results.png に吐き出されます。
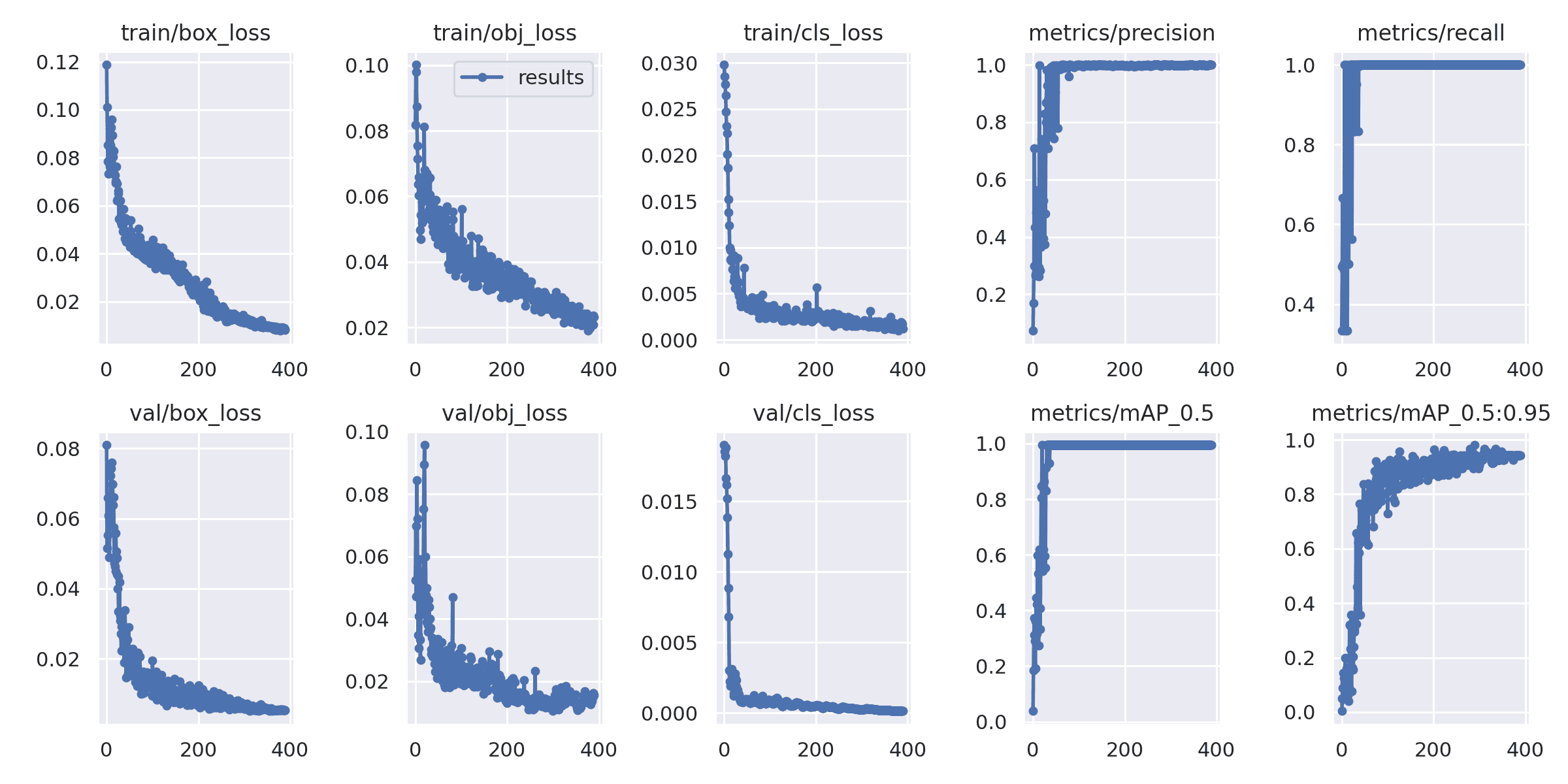
これを見ると、400Epochも回さなくても、200Epochくらいでそこそこの結果が得られそうです。
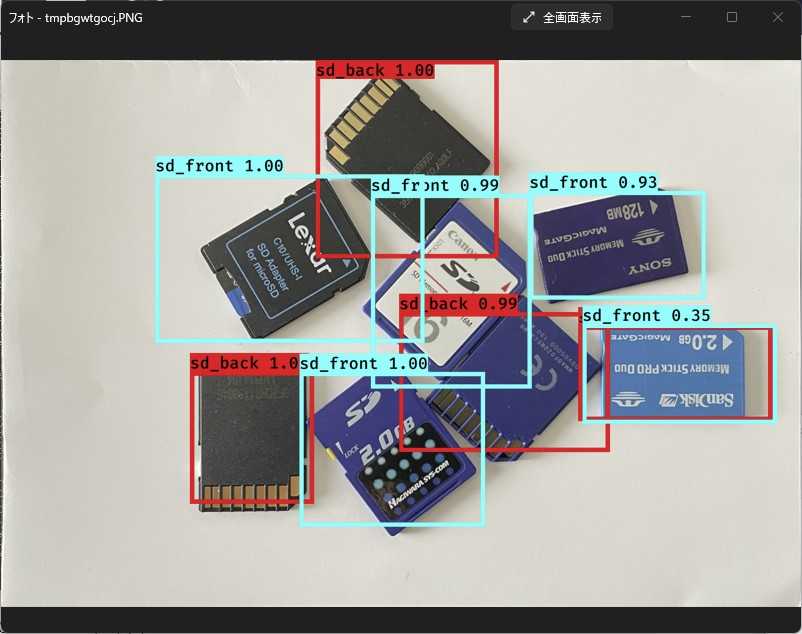
400Epoch学習させた結果で認識させると… yolov3とほぼ同じ結果になりました。

yolov3のときは右端のメモリースティックが裏表同位置認識されて混乱気味でしたが、yolov5ではメモリースティックは表面として認識されています。それ以外はyolov3と同様の結果でした。


今回の実験の追試ガイドはこちら。
追試ガイド(yolov3編)
本記事の内容をyolov3で追試してみたい方向けに、Google Colaboratory上での操作方法をまとめます。
(1) Google Colaboratoryを開く
https://colab.research.google.com/
Google Colaboratory
(2) ノートブックを新規作成
タイトル: yolov3-sdcard.ipynb
(3) ランタイムのタイプを変更
ランタイム>ランタイムのタイプを変更>GPU
(4) Google Driveに接続
Google Drive上のマイドライブにColabという名前のフォルダーを作成し、その中に必要ファイルを全て置いて進めます。
(5) 動作環境構築
Google Colaboratoryのセルに以下のスクリプトを貼り付けてセルを実行
以下のスクリプトでは、筆者のGitHubリポジトリから学習用の画像4枚とスクリプト prepare_training_data_for_yolov3.py を取得しています。prepare_training_data_for_yolov3.py では、学習用の画像4枚から本記事で解説したSDカードをランダム配置した学習用画像100枚と対応するアノテーションファイルtrain.txtを生成しています。
%cd /content/drive/MyDrive
%mkdir Colab
%cd /content/drive/MyDrive/Colab
# パッケージのインストール
!pip install tensorflow==1.14.0
!pip install tensorflow_gpu==1.14.0
!pip install keras==2.2.4
!pip install h5py==2.10.0
!pip install pillow matplotlib opencv-python
# yolov3ダウンロード
!git clone https://github.com/qqwweee/keras-yolo3
# 初期ウエイトダウンロード
%cd keras-yolo3
!wget https://pjreddie.com/media/files/yolov3.weights
# 初期ウエイトをyolov3用に変換
!python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
# yolo_video.pyソース修正
!sed -i -e "s/--model/--model_path/" yolo_video.py
!sed -i -e "s/--anchors/--anchors_path/" yolo_video.py
!sed -i -e "s/--classes/--classes_path/" yolo_video.py
!sed -i -e "s/r_image.show()/r_image.save('temp.png')/" yolo_video.py
# train.pyソース修正(バッチサイズを8にする)
!sed -i -e "s/batch_size = 32/batch_size = 8/g" train.py
# クラスファイル作成
!echo -e "sd_front\nsd_back">model_data/voc_classes.txt
# SDカード学習データの準備
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/prepare_training_data_for_yolov3.py
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_BACK_1.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_BACK_5.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_FRONT_1.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_FRONT_5.jpg
!python prepare_training_data_for_yolov3.py
!touch test.txt
!touch val.txt
# アンカーボックス作成
!sed -i -e s/2012_train.txt/train.txt/g kmeans.py
!python kmeans.py
!cp -p yolo_anchors.txt model_data(6) 学習
%cd /content/drive/MyDrive/Colab/keras-yolo3
!python train.py学習には時間がかかるので、Google Colaboratoryの制限時間内に学習が完了しない場合があります。そうなった場合は、学習が中断した時点から再開させることができます。
yolov3は学習の途中(のチェックポイント)で、それまでに学習した経過を ./logs/000/ フィルダーに出力します。学習が中断した時点でこのフォルダーを覗くと、
epNNN-lossLLLLL-val_lossVVVVV.h5という名前のファイルが多数生成されていることが確認できます。“ep”に続く数字はEpoch番号で、この数字が一番大きいものが直近の学習で進んだEpoch数です。このEpoch数+1から学習を再開させるとよい訳です。
例えば、1回目の学習の結果、 ./logs/000/ フィルダーに以下のようなファイルを残し、「GUP使用上限を超えました」のメッセージが出てGoogle Colaboratoryのセッションが停止したとします。
ep003-loss1465.636-val_loss1039.293.h5
ep006-loss344.617-val_loss342.517.h5
...
ep066-loss34.126-val_loss35.744.h5
ep069-loss34.041-val_loss35.504.h5次の学習はEpoch70から再開すれば良いわけですが、これを実現するには train.py のソースを修正する必要があります。
model = create_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path='model_data/yolo_weights.h5') # make sure you know what you freeze
...
if True:
...
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
...
if True:
...
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=100,
initial_epoch=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
...
train.py の32行目には、学習開始モデルをロードするコードがあります。オリジナルコードでは、初期ウエイト’model_data/yolo_weights.h5’を読み込んでいますが、これをEpoch69のモデル ‘logs/000/ep069-loss34.041-val_loss35.504.h5’ に変更します。
train.py の52行目と70行目に if True: があります。52行目の if True: 以下がEpoch0~Epoch49の実行コードで、70行目の if True: 以下がEpoch50~Epoch99の実行コードです。
Epoch70から再開するためには、52行目の if True: を if False: に変更し、83行目の initial_epoch=50, を initial_epoch=70, に変更すればいいです。
途中再開のソース変更はこんなかんじです。
(7) 認識
学習が完了すると、 logs/000/trained_weights_final.h5 という名前のモデルファイルが生成されるので、このモデルファイルを使って認識を行います。
!python yolo_video.py --model_path logs/000/trained_weights_final.h5 --classes_path model_data/voc_classes.txt --anchors_path model_data/yolo_anchors.txt --image認識結果はローカルでは別ウィンドウに表示されるのですが、Google Colaboratory上では表示されないので代わりに認識結果画像を’temp.png’というファイル名でセーブしています。結果を確認するには、Google Driveをローカルにマウントして マイドライブ/Colab/keras-yolo3/temp.png を見ればよい。
追試ガイド(yolov5編)
本記事の内容をyolov5で追試してみたい方向けに、Google Colaboratory上での操作方法をまとめます。
(1) Google Colaboratoryを開く
https://colab.research.google.com/
Google Colaboratory
(2) ノートブックを新規作成
タイトル: yolov5-sdcard.ipynb
(3) ランタイムのタイプを変更
ランタイム>ランタイムのタイプを変更>GPU
(4) Google Driveに接続
Google Drive上のマイドライブにColabという名前のフォルダーを作成し、その中に必要ファイルを全て置いて進めます。
(5) 動作環境構築
Google Colaboratoryのセルに以下のスクリプトを貼り付けてセルを実行
以下のスクリプトでは、筆者のGitHubリポジトリから学習用の画像4枚とスクリプト prepare_training_data_for_yolov5.py を取得しています。prepare_training_data_for_yolov5.py では、学習用の画像4枚から本記事で解説したSDカードをランダム配置した学習用画像100枚と対応するアノテーションファイルを生成しています。
%cd /content/drive/MyDrive
%mkdir Colab
%cd /content/drive/MyDrive/Colab
# yolov5ダウンロード
!git clone https://github.com/ultralytics/yolov5.git
# パッケージのインストール
%cd /content/drive/MyDrive/Colab/yolov5
!pip install -r requirements.txt
# SDカード学習データの準備
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/prepare_training_data_for_yolov5.py
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_BACK_1.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_BACK_5.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_FRONT_1.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_FRONT_5.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_TEST.jpg
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/SD_TEST.txt
!python prepare_training_data_for_yolov4.py
%cd /content/drive/MyDrive/Colab/yolov5/training
!wget https://github.com/etekichi98/prepare_sdcard_traindata/raw/main/dataset.yaml
#モデルファイル(s/m/l/xのいずれか)をコピー
%cd /content/drive/MyDrive/Colab/yolov5
%cp models/yolov5s.yaml training/
# モデルファイルのクラス数を2にする
!sed -i -e "s/nc: 80/nc: 2/" training/yolov5s.yaml(6) 学習
%cd /content/drive/MyDrive/Colab/yolov5
!python train.py --batch 16 --epochs 200 --data training/dataset.yaml --cfg training/yolov5s.yaml学習結果は runs/train/exp/ に出力されます。
(7) 認識
%cd /content/drive/MyDrive/Colab/yolov5
!python detect.py --source ./SD_TEST.jpg --weights runs/train/exp/weights/best.pt認識結果は runs/detect/exp/ に出力されます。
まとめ
-
SDカードの認識を題材にyolov3, yolov5による機械学習を試してみましたが、yolov5の方が学習結果の可視化イメージとかも出ているいろと便利です。Google Colaboratoryではどの性能のGPUが割り当てられるかが判らず、割り当てられたGPUの性能差も大きいのでyolov3, yolov5の学習スピードがどちらが速いのかはよくわかりません。今回のような案件の学習では認識性能差もはっきりとは出ていません。
-
Google Colaboratoryは無料の範囲でもかなり使えるという印象でした。制限はあるにしても機械学習を爆速でこなすGPUが無料で利用できるのはありがたい。そもそもyoloのような重量級の処理をGPU無しでやるのは無理なわけですから。
-
機械学習が成功するかの鍵は教師画像にあり!認識させたい画像と同じような状態の画像を教師画像にすればうまくいくということが実感できました。