
【実践、おうちで外観検査】機械学習編
April 29, 2022
OpenCV 外観検査 python 機械学習目次
はじめに
前回はOpenCVによるスマホのなんちゃって外観検査に挑戦してみましたが、結果は散々でした。
そこで今回は、機械学習でキズや埃の形状を学習し、それをもとにキズや埃の認識を試みます。使用するのはyolov5です。yoloは画像やビデオ映像中からリアルタイムで学習した物体を認識するために使われますが、キズの認識にも使えるのかな?
学習データの準備
普通にスマホで取った検査対象画像です。ちなみにGoodleのNexus5です。筐体が樹脂製なんで傷がつきやすい。このスマホに傷がないかを撮った画像から検査したいのですが、手持ちのスマホにはいっぱいキズがあるんで、漏れなくキズを抽出したい訳です。

キズをyolov5に学習させるためには、画像中の傷領域をyolov5に教えてあげる必要があります。いわゆるアノテーション付与作業。世の中にはlabelImg等のアノテーション付与のためのツールも公開されており、これらのツールを使用してGUIでインタラクティブにアノテーションを付与することは勿論可能なのですが、大量のアノテーション付与は終りが見えない単純作業であり、精神的にもキツイ作業です。
そこで手抜きして、アノテーションも自動で付与するようにします。
まず、先の画像(4032pixel✕3024pixel)から、512pixel✕512pixelの画像を適当に25枚切り出しました。

これらの25枚の画像をそれぞれ90°、180°、270°回転させて画像を100枚に水増ししました。
これらの画像にアノテーションを付与するのですが、いきなりアノテーション付与ツールを使うのではなく、以下のスクリプトでそれっぽいアノテーションを生成しました。
import cv2
import numpy as np
def shading_correction(img):
kernel = np.ones((15,15),np.uint8)
img_bg = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img_corrected = cv2.absdiff(img_bg, img)
return img_corrected
def make_debris_extents(img):
# ラベリング処理
n, label, data, center = cv2.connectedComponentsWithStats(img)
sizes = data[1:, -1]
# サイズフィルター
rects = []
for j in range(1, n):
if 16<sizes[j-1] and sizes[j-1]<15000:
# 各オブジェクトの外接矩形を抽出
d = 8
w = data[j][2]+d+d
h = data[j][3]+d+d
if 18<=w and w<=256 and 18<=h and h<=256:
x0 = data[j][0]-d
y0 = data[j][1]-d
rects.append((int(x0), int(y0), int(w), int(h)))
return rects
def make_yolo_annotation(img_width, img_height, class_id, xmin, ymin, xmax, ymax):
'''
YOLO形式のアノテーション(yolov5)
'''
xcenter = (xmax + xmin)/img_width/2.0
ycenter = (ymax + ymin)/img_height/2.0
width = (xmax - xmin)/img_width
height = (ymax - ymin)/img_height
annotation_text = '{} {} {} {} {}\n'.format(class_id, xcenter, ycenter, width, height)
return annotation_text
def process_image(image_name):
with open(image_name+'.txt', 'w') as fa:
img_orig = cv2.imread(image_name+'.jpg', 0)
img_result = cv2.cvtColor(img_orig, cv2.COLOR_GRAY2BGR)
img_corrected = shading_correction(img_orig)
ret, img_bin = cv2.threshold(img_corrected, 40, 255, cv2.THRESH_BINARY)
rects = make_debris_extents(img_bin)
for rect in rects:
x0 = rect[0]
y0 = rect[1]
w = rect[2]
h = rect[3]
x1 = x0 + w
y1 = y0 + h
cv2.rectangle(img_result, (x0, y0), (x1, y1), color=(0, 0, 255), thickness=3)
class_id = 0
annotation_text = make_yolo_annotation(
img_orig.shape[1], img_orig.shape[0], class_id,
x0, y0, x1, y1)
fa.write(annotation_text)
# 結果画像を書き出し
cv2.imwrite(image_name+'_result.jpg', img_result)
def main():
for i in range(1,101):
process_image(str(i))
if __name__ == '__main__':
main()100枚の画像 1.jpg~100.jpg からアノテーションファイル 1.txt~100.txt とアノテーションの可視化画像 1_result.jpg~100_result.jpg が生成されます。
このスクリプトでは元画像に対し、シェーディング補正をかけて単純な2値化処理により欠陥を抽出しているだけなので、カメラやロゴや個体識別バーコードの領域にキズではない虚報が大量発生します。これらの虚報をこれをlabelImgを使って確認し、取捨選択していきます。labelImgはpipでインストールできます。
画像とアノテーションを以下のような構成のフォルダーに入れておきます。
train/
images/
*.jpg
labels/
classes.txt
*.txtclasses.txtは分類クラス名を記述するファイルです。今回はキズ1種類1クラスのみを学習させるので、1行だけ必要です。例えば、クラス名をdebrisとしたいなら、classes.txtは以下の内容にします。
debrislabelImgの「Open Dir」で train/images フォルダーを指定し、「Change Save Dir」で train/labels フォルダーを指定すると、アノテーションをインタラクティブに編集できるようになります。ここで虚報を片っ端から削除します。
個体識別バーコードの領域に大量発生した虚報
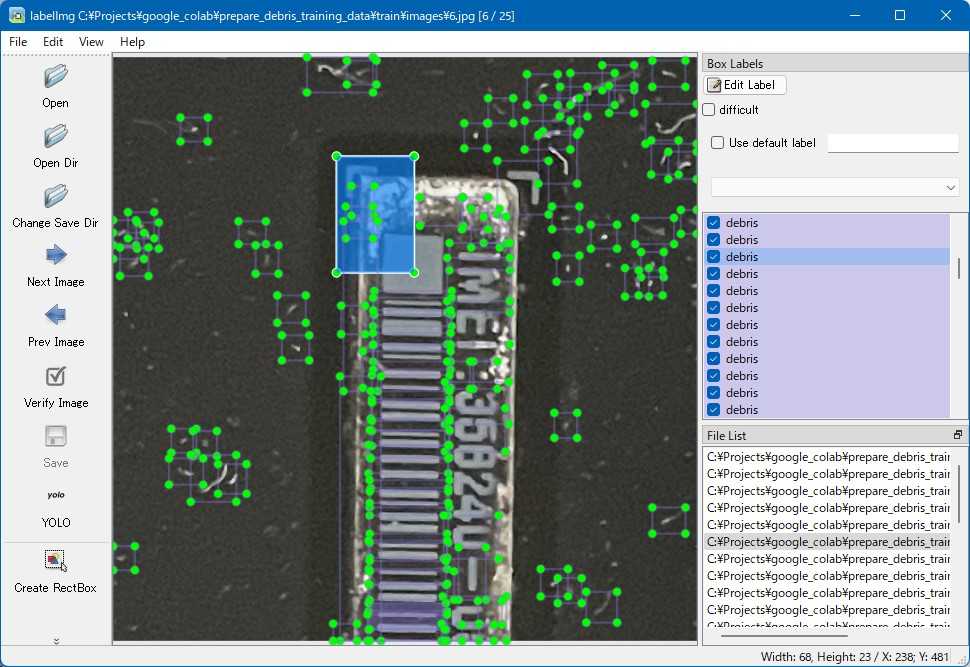
虚報を取り除いた後のアノテーション

アノテーションの準備ができたら、yolov5による学習に必要なファイル一式をフォルダーにまとめておきます。
training/
dataset.yaml
yolov5s.yaml
train/
images/
*.jpg
labels/
classes.txt
*.txt
test/
images/
*.jpg
labels/
classes.txt
*.txt
val/trainフォルダーの画像はyolov5が学習で使用し、testフォルダーの画像はyolov5が評価で使用します。今回は100画像中90画像をtrainに10画像をtestにしました。
dataset.yamlには学習画像、評価画像の場所、クラス数、クラス名を記述します。
# train and val datasets (image directory or *.txt file with image paths)
train: training/train/images
val: training/test/images
# number of classes
nc: 1
# class names
names: ['debris']yolov5s.yamlは、yolov5/models/フォルダーからコピーしてきたもので、ファイルの4行目のクラス数を1に書き換えています。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
...
以上で学習データの準備は完了です。
Google Colaboratory上で学習
学習データの準備が出来たら、あとはyolov5で学習させるだけですが、GPUが使えないPCだと途方もない時間がかかりやってられません。そこで、ブラウザから高性能GPUが使える環境であるGoogle Colaboratoryを利用してみます。
(1) Google Colaboratoryにアクセスし、
https://colab.research.google.com/?hl=ja
「ノートブックを新規作成」をクリック
ノートブックのタイトル: yolov5-debris.ipynb
これは適当に。
(2) ランタイムのタイプを変更
ランタイム>ランタイムのタイプを変更>GPU
(3) Google Driveに接続
(4) yolov5ダウンロードと実行に必要なパッケージのインストール
Google Drive上に環境を構築していきます。
%cd /content/drive/MyDrive
%mkdir Colab
%cd /content/drive/MyDrive/Colab
# yolov5ダウンロード
!git clone https://github.com/ultralytics/yolov5.git
# パッケージのインストール
%cd /content/drive/MyDrive/Colab/yolov5
!pip install -r requirements.txt(5) 学習データをGoogle Driveにコピー
(4)まで終えたら、Google Draiveの マイドライブ/Colab/yolov5 ディレクトリが出来ていますので、ここに「学習データの準備」で作成したtrainingフォルダーをコピーします。
(6) 学習
epoch数は400としましたが、適当に。学習が収束すればepoch数未満でも止まってくれます。
%cd /content/drive/MyDrive/Colab/yolov5
!python train.py --batch 16 --epochs 400 --data training/dataset.yaml --cfg training/yolov5s.yaml学習は、その時割り当てられたGPUの性能にもよりますが、小一時間で終わるでしょう。
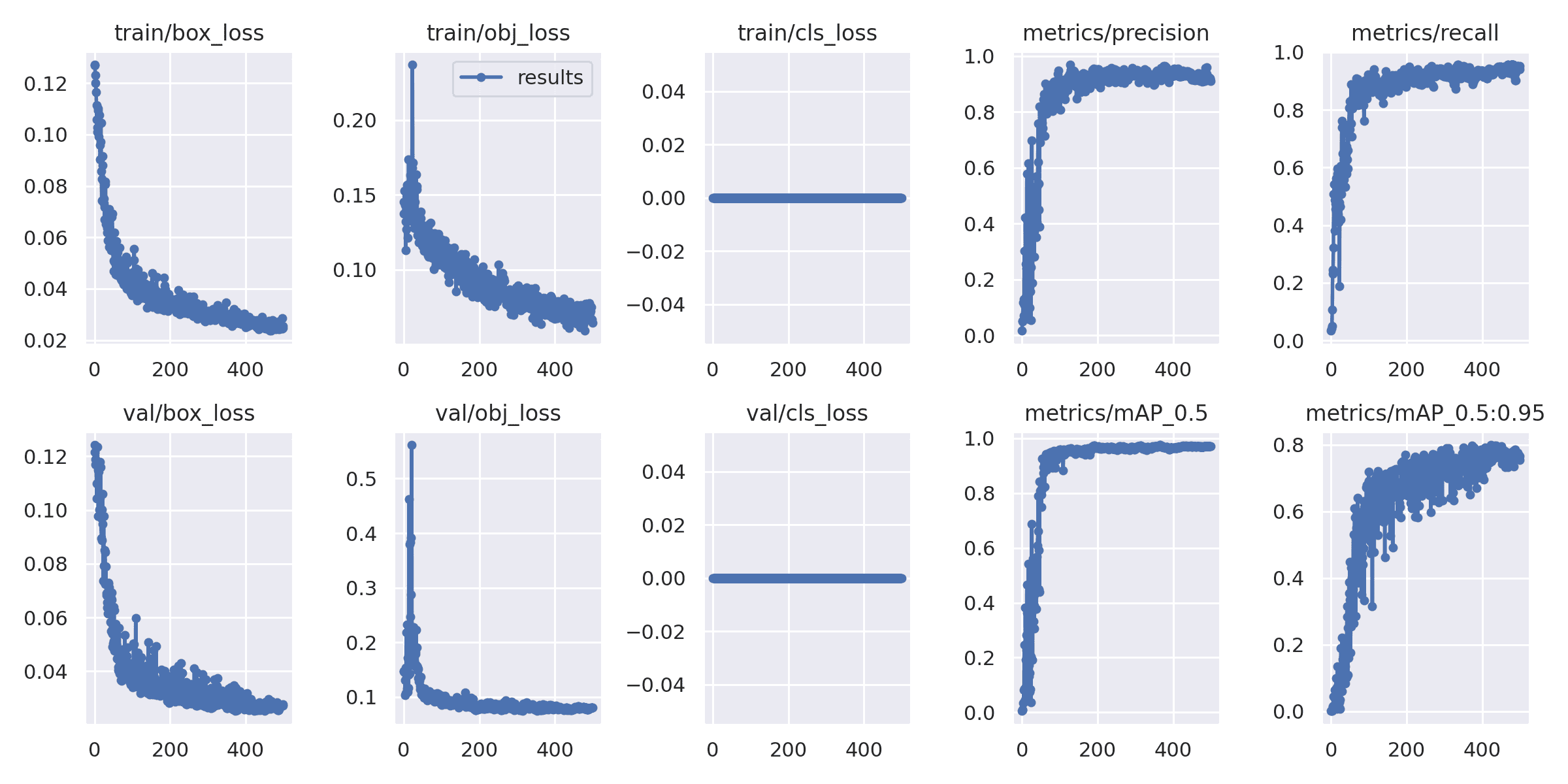
学習が完了すると、 /content/drive/MyDrive/Colab/yolov5/runs/train/exp (Google Driveで見ると マイドライブ/Colab/yolov5/runs/train/exp)に学習結果一式が生成されます。results.png を見て、学習を重ねるにつれlossが順調に減っていき、precisionが順調に上がっていくことが確認できれば成功です。
(7) 認識
認識させたい画像(例えば train_image.jpg, test_image.jpg)をGoogle Drive の マイドライブ/Colab/yolov5 にコピーし、detect.py を実行します。
%cd /content/drive/MyDrive/Colab/yolov5
!python detect.py --source ./train_image.jpg --weights runs/train/exp/weights/best.pt
!python detect.py --source ./test_image.jpg --weights runs/train/exp/weights/best.pt/content/drive/MyDrive/Colab/yolov5/runs/detect/exp*/*.jpg に認識結果画像が生成されます。
学習画像を切り出した元画像を認識させても見落としが多い…

それとば別の画像(光源が上下逆)だと、さらに見落としが多い…

このままだと、実用には程遠いかな。
おわりに
今回はyolov5を使用し機械学習によるスマホの外観検査(キズ認識)をやってみました。結果はいまいちでちょっと詰めが甘いかんじですが、雰囲気は感じとっていただけたかと思います。
今回はキズ単一クラスの認識でしたが、学習データが揃えられればキズと埃の2クラス学習とか、キズの原因別にクラス分けするとか、キズの分類もできそうな気がします。いわゆるADC(Automatic Defect Classification)。そこまでいけばカッコいいんですが…先は遠そう。