
【第3回】無尽蔵株価データから銘柄毎の時系列データを生成
December 11, 2020
株価サーバー python無一物中Project記事一覧
- 【第1回】株価サーバーの構築の概要
- 【第2回】無尽蔵から株価データの一括取得
- 【第3回】無尽蔵株価データから銘柄毎の時系列データを生成(本記事)
- 【第4回】無尽蔵から自動で株価データを取得し株価データベースを更新
- 【第5回】出来ず株価の補填と株式分割を自動調整してチャート表示
- 【第6回】mplfinanceを使用してテクニカルチャート表示
- 【第7回】テクニカル指標による銘柄スクリーニング
- 【第8回】株価チャート配信サーバー
- 【第9回】チャート形状の認識
はじめに
毎日の日本株の株価データを公開している無尽蔵というサイトがあります。
本記事では、無尽蔵サイトから取得した毎日の株価データから、銘柄毎の株価日足時系列データを生成し、チャート表示させてみます。無尽蔵サイトから毎日株の価データを一括ダウンロードする方法はこちらを参照してください。
銘柄毎の株価日足時系列データの生成
無尽蔵サイトの株価データは、以下のような形式のcsvファイルです。
2020/12/1,1001,11,1001 日経225,26624,26852,26618,26788,1331220000,東証1部
2020/12/1,1002,11,1002 TOPIX,1765,1772,1760,1768,1331220000,東証1部
2020/12/1,1301,11,1301 極洋,2824,2824,2780,2787,17900,東証1部
2020/12/1,1305,11,1305 ダイワTPX,1851,1862,1850,1857,575180,東証1部
2020/12/1,1306,11,1306 TOPIX投,1831,1840,1828,1835,2675730,東証1部
...
2020/12/1,1712,31,1712 ダイセキ環境,0,0,0,0,0,名古1部
2020/12/1,1712,11,1712 ダイセキ環境,686,689,682,688,35700,東証1部
...
2020/12/1,9996,91,9996 サトー商会,1440,1470,1424,1454,1700,JAQ
2020/12/1,9997,11,9997 ベルーナ,959,962,938,954,154000,東証1部無尽蔵サイトから、必要な期間の株価データTyymmdd.csvを取得し、それらから銘柄毎の株価日足時系列データを生成します。
生成する株価日足時系列データのcsvファイルの例は以下。
2015/01/05,275,277,274,275,239000000
2015/01/06,274,275,270,272,480000000
2015/01/07,270,273,270,271,217000000
...
2020/11/25,2839,2846,2795,2831,27800000
2020/11/26,2820,2826,2801,2809,8700000
2020/11/27,2807,2825,2803,2819,22000000以下のディレクトリ構成を前提としています。
daily_dataディレクトリには、年毎のサブディレクトリを切り、その中に、無尽蔵サイトから取得したcsvファイルを置きます。
dataディレクトリには、証券コードの1000の桁毎のサブディレクトリを切り、その中に、銘柄毎の株価日足時系列データのcsvファイルが置かれます。
daily_dataディレクトリの中を読んで、dataディレクトリの中にデータを吐き出すスクリプトを作る訳です。
working_root/
daily_data/
2015/
T150105.csv
...
...
2020/
T200106.csv
T200107.csv
...
T201120.csv
data/
1000/
1001.csv
1002.csv
...
2000/
...
9000/
9001.csv
...単なる力業の実装例ということで、スクリプト例は以下です。このスクリプトをそのまま実行する場合は、daily_data/以下のディレクトリとdata/以下のディレクトリは、あらかじめ作っておいてください。 main()の入力ディレクトリの期間も、取得したデータにあわせて調整してください。
# -*- coding: utf-8 -*-
import glob
import os
def add_data(code, date_str, cv1, cv2, cv3, cv4, cvc):
code_dir = code[0]+"000"
out_path = "./data/" + code_dir + "/" + code + ".csv"
line = date_str+','+cv1+','+cv2+','+cv3+','+cv4+','+str(int(float(cvc)*1000))+'\n'
with open(out_path,'a') as f:
f.write(line)
def import_daily_data(import_year):
daily_files = glob.glob('./daily_data/{}/*.csv'.format(import_year))
for daily_file in daily_files:
filename = os.path.basename(daily_file)
yy = 2000 + int(filename[1:3])
mm = int(filename[3:5])
dd = int(filename[5:7])
date_str = '{0:4d}/{1:02d}/{2:02d}'.format(yy, mm, dd)
with open(daily_file, mode='rb') as fd:
lines = fd.readlines()
for i, line in enumerate(lines):
try:
line = line.decode('cp932')
except:
print('error file {}: line {}'.format(daily_file, i))
# utf-8でないバイト列が含まれる行はスキップする
continue
line = line.rstrip()
line_list = line.split(',')
if len(line_list)==10:
if len(line_list[1])==4:
code = str(line_list[1])
market = line_list[9]
if '名古' in market:
next_line = lines[i+1]
next_line = next_line.decode('cp932')
next_line_list = next_line.split(',')
next_code = str(next_line_list[1])
if next_code!=code:
add_data(code, date_str, line_list[4], line_list[5], line_list[6], line_list[7], line_list[8])
else:
add_data(code, date_str, line_list[4], line_list[5], line_list[6], line_list[7], line_list[8])
else:
print('error file {}: line {} : {}'.format(daily_file, i, line))
def main():
for year in range(2015, 2021):
import_daily_data(year)
if __name__ == '__main__':
main()以下のように実行します。
$ python import_daily_data.py以上で、data/ディレクトリ以下に銘柄毎の時系列csvファイルが生成されました。
import pandas as pd
import mplfinance as mpf
path = './data/1000/1001.csv'
df = pd.read_csv(path, header=None, names=['Date','Open','High','Low','Close','Volume'], encoding='UTF-8')
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index("Date")
mpf.plot(df, type='candle', volume=True)$ python simple_plot.py結果はこれ。
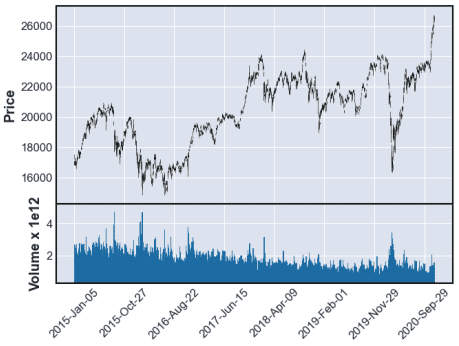
一見、これでよさげだけど、例えば、和製コストコでおなじみの業務スーパーを運営する「3038神戸物産」のチャートを見てみると、
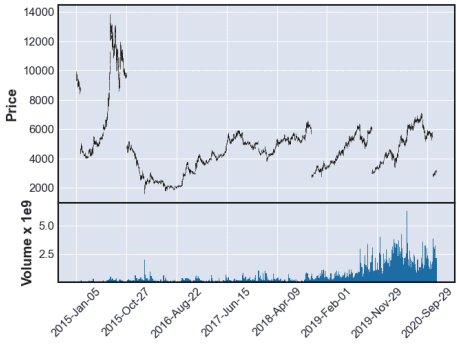
株式分割の調整ができていないんで、このままでは、使い物にならない。
株式分割の調整機能については、こちらを参照のこと。
まとめ
無一物中Project第3回では、無尽蔵サイトから取得した株価データから株価データベース(銘柄毎の時系列データ)を構築するpythonスクリプトを紹介しました。